
Managing Editor
@ShahidNShah
@ShahidNShah

We’re all familiar with the idea that medicine is, slowly but surely, going from a paper-native to a digital-native industry. Most of our processes and procedures were designed in an environment where information started on paper and then was either scanned as a PDF document or entered into a structured electronic record in some software. Our current processes assume that if our software systems ever failed, we have paper records and could continue standard medical care without the electronic versions for a period of time. As our reliance on EHRs and other health IT systems increases, those assumptions of paper-based failover are probably no longer valid and we need to make sure we have new processes in place that understand how data is created, where it’s stored, how it’s backed up, how it’s archived, and how we can recover it in a disaster scenario. All of these kinds of tasks are grouped into a field known as “Information Lifecycle Management” – which is just a fancy way of saying that we manage data in disciplined, not ad-hoc manner.
In the paper world, all information is generally treated the same – namely, it’s a group of sheets of paper and documents which are, at most, grouped together in folders. Regardless of whether that data is demographic in nature, clinical in nature, a radiology image, a lab test result, etc. doesn’t really matter when it’s on paper and just needs to be filed. But, when it’s electronic in nature, the way we treat each kind of data and its digital lifecycle becomes important. For example, take a look at the kinds of data we’re being asked to manage (click the image to see a higher resolution version):
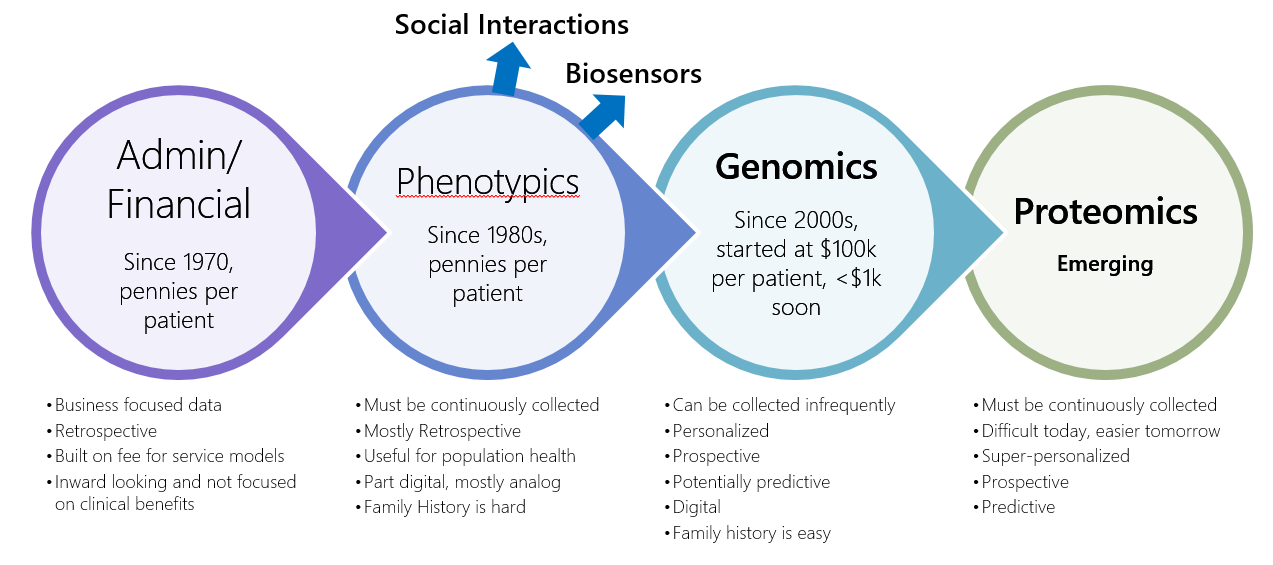
If you don’t have a disciplined ILM approach, how would you approach the management of the dozens of kinds of the following unstructured types data sources?
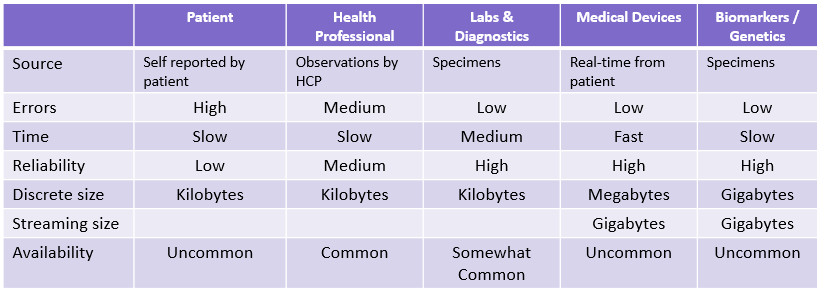
If you think managing unstructured data is hard, how would you approach the management of the many of kinds of the following structured types data sources?
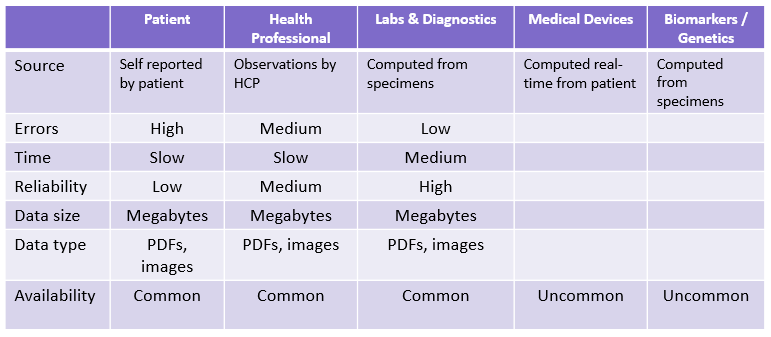
If you’re wondering how to get started with a more disciplined ILM approach, check out some of my video interviews on the subject:
[youtube=http://www.youtube.com/watch?v=x3eTJ1P9NJE&w=520]
If you’re interested in even more advice, check out the rest of the data and ILM related video series on YouTube.

Shahid Shah is an internationally recognized enterprise software guru that specializes in digital health with an emphasis on e-health, EHR/EMR, big data, iOT, data interoperability, med device connectivity, and bioinformatics.
Connecting innovation decision makers to authoritative information, institutions, people and insights.

Medigy accurately delivers healthcare and technology information, news and insight from around the world.
Medigy surfaces the world's best crowdsourced health tech offerings with social interactions and peer reviews.
© 2025 Netspective Media LLC. All Rights Reserved.
Built on Mar 12, 2025 at 5:07am


